EnsembleCore AI
| Introduction: | EnsembleCore AI is a Model Shrinking Platform designed to reduce training and inference costs for machine learning models without sacrificing performance. |
| Recorded in: | 6/4/2025 |
| Links: |
What is EnsembleCore AI?
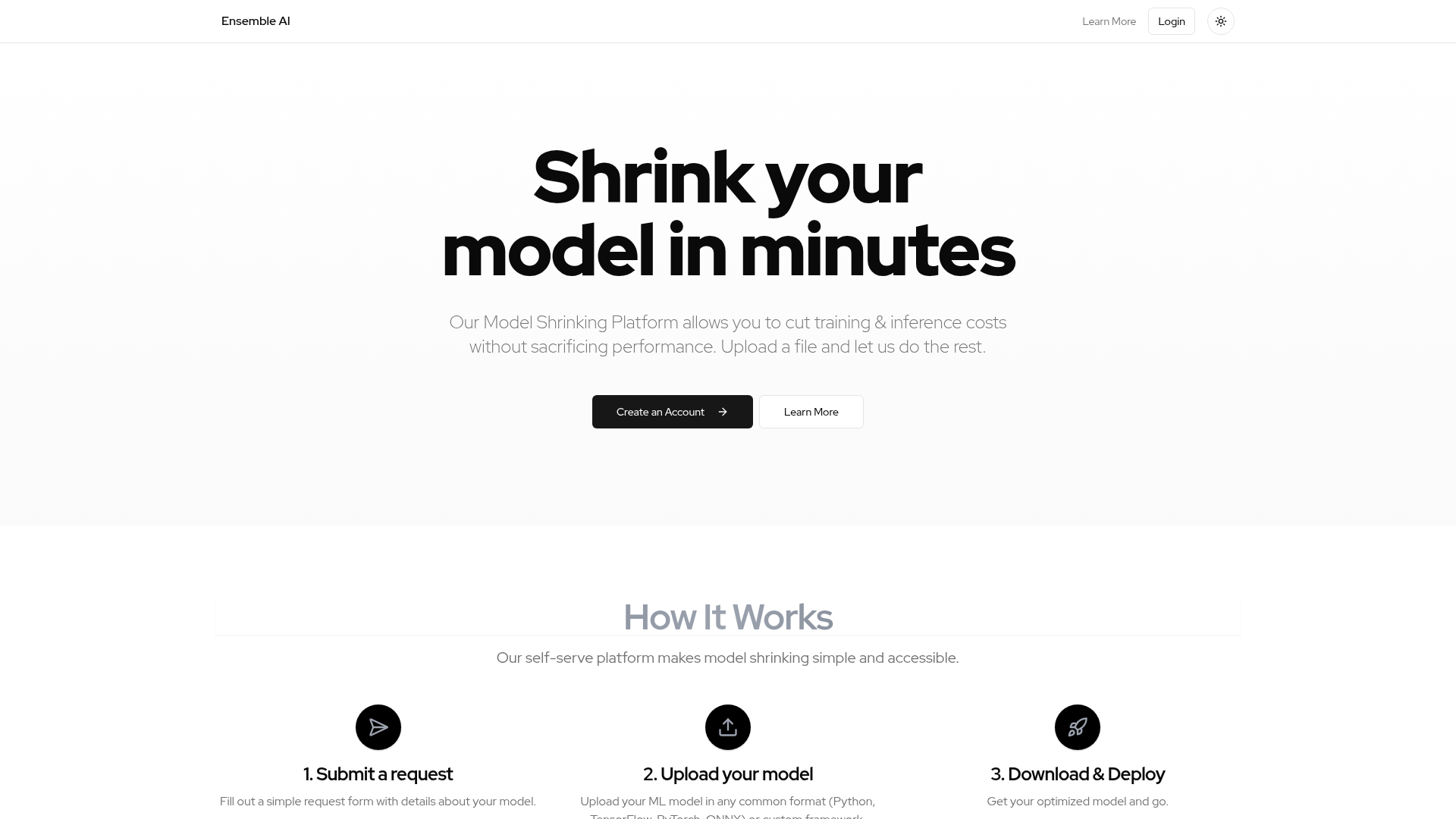
EnsembleCore AI is a self-serve Model Shrinking Platform that enables users to significantly cut down on the training and inference costs associated with their machine learning models, all while maintaining or improving performance. It is designed for developers and organizations working with ML models who seek efficiency and cost-effectiveness in their AI operations. The platform provides a streamlined process for optimizing models, making advanced model shrinking techniques accessible to a broader audience.
How to use EnsembleCore AI
Users interact with EnsembleCore AI through a simple, self-serve web platform. To get started, users need to create an account. The process involves three main steps: first, submitting a request form with details about their model; second, uploading their machine learning model, which can be in common formats like Python, TensorFlow, PyTorch, ONNX, or even custom frameworks; and finally, downloading the optimized model ready for deployment. The platform handles the complex optimization process automatically after the model is uploaded.
EnsembleCore AI's core features
Model shrinking and optimization
Reduction of training and inference costs
Preservation of model performance
Support for multiple ML model formats (Python, TensorFlow, PyTorch, ONNX)
Compatibility with custom ML frameworks
Self-serve platform interface
Simple request submission process
Automated optimization process
Downloadable optimized models
Use cases of EnsembleCore AI
Reducing operational costs for large-scale AI deployments.
Optimizing models for deployment on resource-constrained edge devices.
Accelerating inference speeds for real-time applications and services.
Improving the efficiency of machine learning pipelines in production environments.
Making large language models (LLMs) or other complex models more manageable and cost-effective.
Streamlining model deployment workflows by providing optimized assets.