EnsembleCore AI
| Introducción: | EnsembleCore AI es una Plataforma de Reducción de Modelos diseñada para disminuir los costos de entrenamiento e inferencia de modelos de aprendizaje automático sin sacrificar el rendimiento. |
| Registrado en: | 6/4/2025 |
| Enlaces: |
¿Qué es EnsembleCore AI?
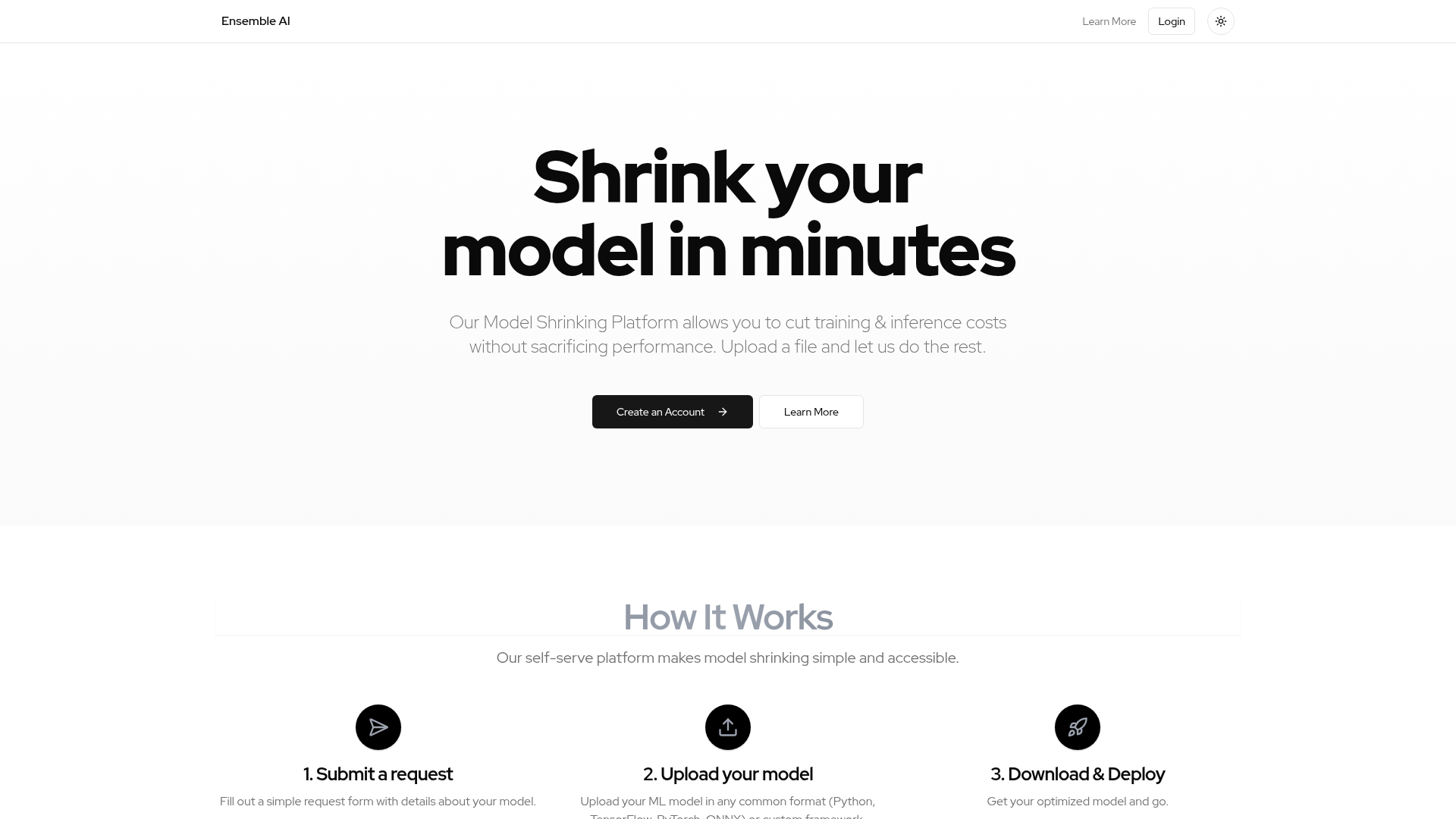
EnsembleCore AI es una Plataforma de Reducción de Modelos de autoservicio que permite a los usuarios reducir significativamente los costos de entrenamiento e inferencia asociados con sus modelos de aprendizaje automático, manteniendo o incluso mejorando el rendimiento. Está diseñada para desarrolladores y organizaciones que trabajan con modelos de ML y buscan eficiencia y rentabilidad en sus operaciones de IA. La plataforma ofrece un proceso optimizado para la optimización de modelos, haciendo que las técnicas avanzadas de reducción de modelos sean accesibles para una audiencia más amplia.
Cómo usar EnsembleCore AI
Los usuarios interactúan con EnsembleCore AI a través de una plataforma web de autoservicio sencilla. Para empezar, los usuarios deben crear una cuenta. El proceso consta de tres pasos principales: primero, enviar un formulario de solicitud con los detalles de su modelo; segundo, cargar su modelo de aprendizaje automático, que puede estar en formatos comunes como Python, TensorFlow, PyTorch, ONNX, o incluso frameworks personalizados; y finalmente, descargar el modelo optimizado listo para su implementación. La plataforma gestiona automáticamente el complejo proceso de optimización una vez que se carga el modelo.
Características principales de EnsembleCore AI
Reducción y optimización de modelos
Reducción de costos de entrenamiento e inferencia
Preservación del rendimiento del modelo
Soporte para múltiples formatos de modelos de ML (Python, TensorFlow, PyTorch, ONNX)
Compatibilidad con frameworks de ML personalizados
Interfaz de plataforma de autoservicio
Proceso sencillo de envío de solicitudes
Proceso de optimización automatizado
Modelos optimizados descargables
Casos de uso de EnsembleCore AI
Reducir los costos operativos para implementaciones de IA a gran escala.
Optimizar modelos para su implementación en dispositivos de borde con recursos limitados.
Acelerar las velocidades de inferencia para aplicaciones y servicios en tiempo real.
Mejorar la eficiencia de los pipelines de aprendizaje automático en entornos de producción.
Hacer que los modelos de lenguaje grandes (LLM) u otros modelos complejos sean más manejables y rentables.
Agilizar los flujos de trabajo de implementación de modelos al proporcionar activos optimizados.